Content Outline
Imagine you had 13,000 e-mail subscribers, with no other detail but their .coms. Imagine you had to send out e-mail content to these subscribers, without any context or insight as to who they are.
Can you picture the disastrous open and click-through rates, brought about by generic one-message-fits-all emails? We can. We don’t even have to imagine—we’ve been there.
It’s a fact that marketers need as much information about who they communicate with, in order to send contextually aware, or even just relevant messages. Even simple information goes a long way—company details, industry, their position, geographic location—in allowing certain amounts of segmentation within your list, which for you means better reception to your marketing material.
So, how exactly do you go about getting information for 13,000 e-mail addresses? Through web scraping or data mining—which we will share with you today.

What Is Scraping?
In a nutshell, scraping is the act of obtaining information by writing a code that automatically taps on a company’s Application Program Interface (API, variable on whether free or paid), by extracting the information you need from a page’s source code, or by directly capturing information on the screen (screen capping). You will usually need a fundamental understanding of programming language like R or Python, but these days, there are written programs and web browser extensions that can achieve similar results.
Scraping can help your business by building or enriching profiles with information that you can find on social media or the Internet. Naturally, there are other use cases for scraping, such as customer segmentation, lead generation, and competitor sentiment analysis. Information is power, and how you use it (within legal confines) is limited to your imagination.
Long story short? Most of the time, you can automate the process of information-gathering with scraping, saving you significant amounts of time.
How much time exactly?
Let’s go back to the example we mentioned in the beginning of 13,000 email addresses. If a person takes 1 minute to search for the name inside an email address, visit a relevant website and record the information, it will take them 217 man hours, or more than 5 business weeks to finish that task.
Using a conservative estimate of 10 seconds per query, a computer can complete this task in 36 continuous hours.
That’s 181 hours saved… but wait! The reality is that it takes time to code an automation, check the data, and fill in some missing or erroneous results, so actual completion could potentially take around a week.
Even so, would you say no to completing a task in a week over five—which is about a 500% gain in time?
As we say, “the proof is in the pudding”—so now that you know about the why’s and what’s of scraping, I have included an example here to walk you through the how.
You can download or fork from our GitHub and try this code for yourself. This code will not work until you have done a one-time setup with Google’s affiliated services. Google provides an entire step-by-step tutorial here.
Scraping Data with an API to Add Value to your Business
Note: If coding is not your cup of tea, you can just read the bolded sections.
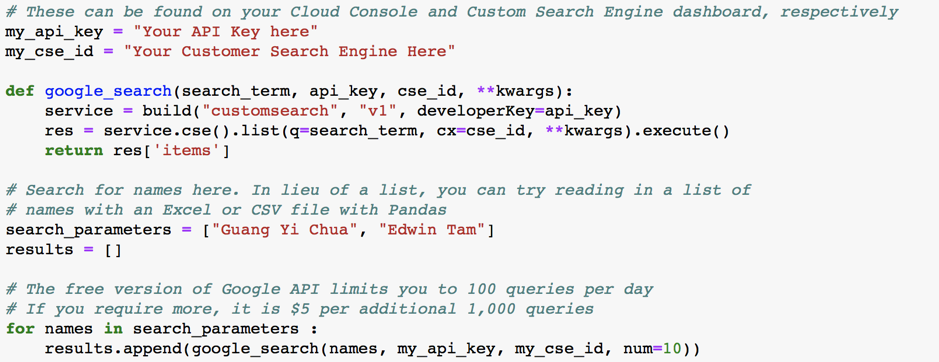
Essentially, my code makes use of Google’s JSON Custom Search API. Returning to our email address problem, assume I have gone through the email addresses and extracted first and last names to search. Reading the names into a list, the API will query each item in the list and save the first 10 results. Change this value under the variable “num” if you wish to save and capture more hits.
Once the search has finished running, Python saves the results in JSON format. This is hard to understand and does not make much sense!
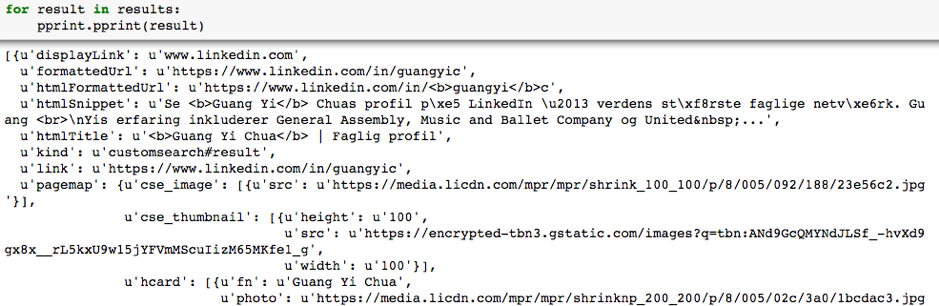
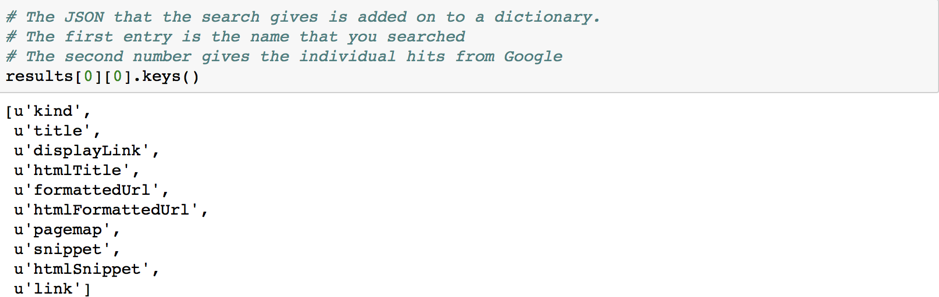
From the dictionary keys, we extract the relevant columns of interest into a Pandas DataFrame.

You have found the top 10 search results for your people of interest, and using further analysis on your newfound information, you can better target and segment your prospects and customers!
This script also works with company names found in email addresses, and I limited search results to only include LinkedIn company pages, as these pages have a great deal of useful information (e.g. number of employees, city headquarters, industry, etc.)

After some filtering and formatting, the results look like this:
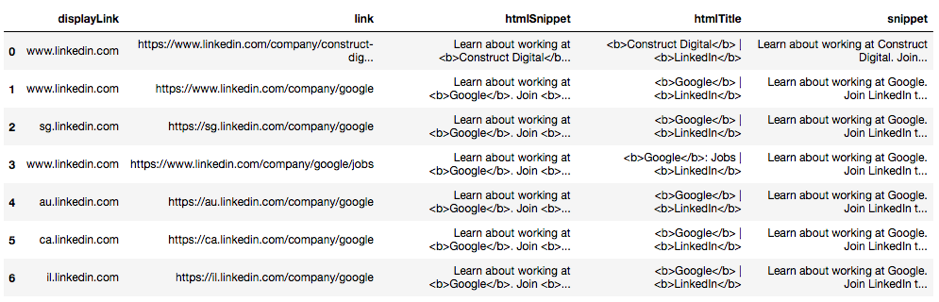
From here, export and put it on your database. Remember, should you require a large number of queries, Google’s API requires payment.
Congratulations on completing your first data scraping exercise! However, before you go out and scrape the entire Internet, please bear the following considerations in mind.

Considerate and Ethical Scraping
If the site or company provides you with an API, everything accessible through that API is considered public information. What happens if there is no API or the API does not give you the information you need?
This is where we fall back on our own scrapers. First and foremost, respect people’s privacy! If the information is not public, do not go digging for it. With this in mind, also do these things before running your scraper:
1. Check the robots.txt file
2. Enough time between requests
3. Identify yourself
Check the Robots.txt File
You can always find this page by appending “/robots.txt” to the end of the main URL. For example:
Generally, any mining tools we write will fall under the “User-agent” portion of the page. Here are a some of the most common listings:
 Source: https://varvys.com/robottxt.html
Source: https://varvys.com/robottxt.html
If you require a more comprehensive explanation on how to understand the robots.txt page, here is an excellent reference.
Enough Time Between Requests
Limit the speed of your queries; hitting a website with a hundred requests per second is tantamount to a cyberattack and willget your IP suspended and/or banned.
One query every 5-10 seconds is fine. Also, try to run your script during off-peak/non-business hours, as you will be less likely to stress the site’s resources with your flood of queries.
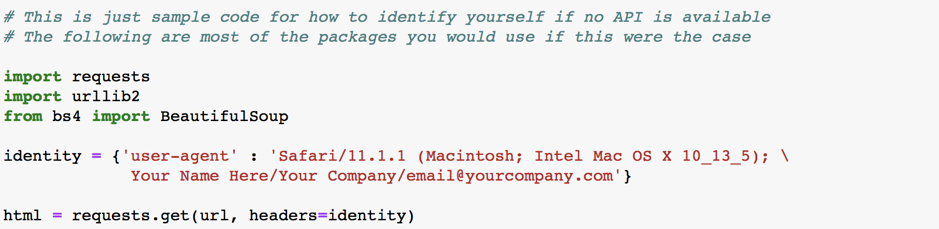
Identify Yourself
(Quick note: You only have to do this if you are accessing the website without using an API. If you are using the company’s API, you already provided your details.)
Identifying yourself serves dual purposes: it lets the site administrator(s) know that you are not mounting a cyberattack on them, and it gives them a way to contact you, which is their right because the information is theirs to start with!
The following script is a quick example of how to format your identity and return it as part of your queries.
Just by following these simple guidelines, your responsible scraping means websites will continue to allow access to everyone.

Final Disclaimers
We are not endorsing scraping for unethical use, and this guide serves as a knowledge repository for marketeers who operate within the confines for PDPA and greater GDPR laws—which do not specifically cover web scraping but has implications for scrapers in terms of what they do with the data (selling, commercializing, reproducing, infringing).
We are strong advocates of data protection and privacy. As a crash course, here is a refresher article on PDPA vs GDPR. As a reminder, here are some major sites which explicitly tell you NOT to scrape their data:
- eBay
- Taobao
Data@Construct
This is just one of the many ways we are helping marketers across the region to increase their Digital Marketing ROI and Effectiveness. Other problems we can help you solve include (but are not limited to!) creating and managing your data pipeline, deriving insights from customer data, and predicting sales decisions from your sales data.
If you have a question about what we wrote here, or have a marketing data problem that needs cracking, drop us a line for a chat. We’re friendly. Promise.

Additional reading
- http://robertorocha.info/on-the-ethics-of-web-scraping/
- https://medium.com/@cfiesler/law-ethics-of-scraping-what-hiq-v-linkedin-could-mean-for-researchers-violating-tos-787bd3322540
- http://www.storybench.org/to-scrape-or-not-to-scrape-the-technical-and-ethical-challenges-of-collecting-data-off-the-web/
- https://dailydatanews.com/2018/01/17/web-scraping/
- https://quickleft.com/blog/is-web-scraping-ethical/

About the Author

Guang Yi
Guang Yi self-identifies as a scientist, musician, and all-around nerd. He serves as a Marketing Analyst at Construct, and spends most of his time messing around with datasets. A long time ago, he wrote (largely for himself) emo posts on LiveJournal, Xanga, and Wordpress, and was delighted when Construct asked him to write articles of substance(!) for their blog.

Guide
Assess Your IMPACT
Try our IMPACT scorecard to discover how your marketing stacks up across our six-pillar framework. Get a data-driven scorecard that identifies gaps and opportunities for measurable growth.